Gen AI for Product Manager 1
In this article, we will learn the end-to-end process of using Gen AI in Building Products. This process starts with ideation and identifying the use case, then getting the right training data, Choosing the right Model and then Deployment. We will cover the entire lifecycle.
- How to preprocess data for generative AI?
→ Data Collection
→ Data Cleaning
→ Data Formatting
→ Additional Constraints - How do you choose an AI Model?
→ Choosing the Right Model
→ Training the Model
→ Applications across different Industries - How do you deploy Gen AI Models?
→ Integration into Existing System
→ Ensuring Reliability and Scalability
Understanding the Role of Gen AI in Product Strategy
Gen AI can play a multifaceted role in product strategy, from ideation and market analysis to product development and go-to-market planning.
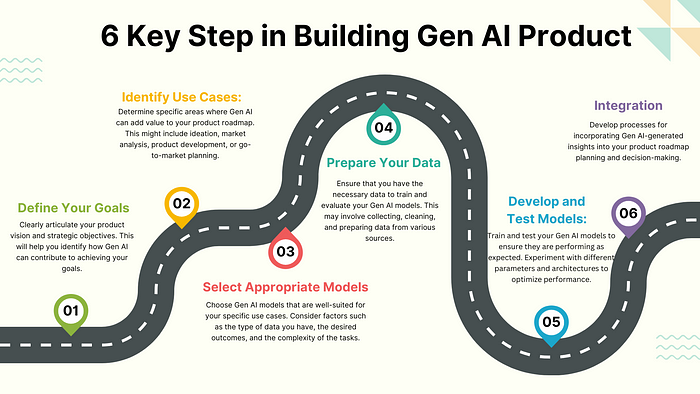
Integrating Gen AI into product roadmaps involves several key steps:
- Define Your Goals: Clearly articulate your product vision and strategic objectives. This will help you identify how Gen AI can contribute to achieving your goals.
- Identify Use Cases: Determine specific areas where Gen AI can add value to your product roadmap. This might include ideation, market analysis, product development, or go-to-market planning.
- Select Appropriate Models: Choose Gen AI models that are well-suited for your specific use cases. Consider factors such as the type of data you have, the desired outcomes, and the complexity of the tasks.
- Prepare Your Data: Ensure that you have the necessary data to train and evaluate your Gen AI models. This may involve collecting, cleaning, and preparing data from various sources.
- Develop and Test Models: Train and test your Gen AI models to ensure they are performing as expected. Experiment with different parameters and architectures to optimize performance.
- Integrate into Your Workflow: Develop processes for incorporating Gen AI-generated insights into your product roadmap planning and decision-making.
How to preprocess data for generative AI?
Data preparation is a critical step in the development of generative AI models. The quality and quantity of your data will significantly impact the performance and effectiveness of your AI system. This section will delve into the key aspects of data preparation, including data collection, cleaning, and formatting.
Data Collection
The first step in data preparation is to collect a sufficient amount of high-quality data. This data should be representative of the task you want your AI model to perform. Consider the following sources:
- Internal Data: This includes data generated within your organization, such as customer data, product usage data, and operational data.
- External Data: This can include publicly available datasets, industry benchmarks, or data purchased from third-party vendors.
- Synthetic Data: If real-world data is scarce or difficult to obtain, you can generate synthetic data using AI techniques. This can be particularly useful for tasks such as medical image analysis or autonomous driving.
Data Cleaning
Once you have collected your data, it’s essential to clean it to remove errors, inconsistencies, and outliers. This process involves several steps:
- Missing Data Handling: Identify and address missing data points. You can either remove missing data, impute values, or use techniques like k-nearest neighbors or regression.
- Outlier Detection and Removal: Detect and remove outliers that can skew your data and affect model performance.
- Data Normalization: Scale your data to a common range to ensure that features are treated equally by the model.
- Data Standardization: Convert data to a standardized format, such as z-scores, to improve model performance.
- Feature Engineering: Create new features or transform existing features to capture relevant information and improve model accuracy.
Data Formatting
- Data Structure: Ensure that your data is in a consistent and structured format, such as CSV, JSON, or a database.
- Labeling: If your task involves supervised learning, ensure that your data is properly labeled with the correct target variables.
- Data Splitting: Divide your data into training, validation, and testing sets to evaluate model performance and prevent overfitting.
Additional Considerations
- Data Quality: The quality of your data is crucial for the success of your generative AI model. Ensure that your data is accurate, relevant, and representative of the task you want to accomplish.
- Data Privacy and Security: Protect sensitive data and comply with relevant privacy regulations.
- Data Diversity: A diverse dataset can help your model generalize better and avoid biases.
- Data Augmentation: If you have limited data, consider data augmentation techniques to create new training examples.
How do you choose an AI model?
Once you have prepared your data, the next crucial step is to select and train a suitable generative AI model. This involves understanding the different types of models available, their strengths and weaknesses, and the best practices for training them effectively.

Choosing the Right Model
The choice of generative AI model depends on the specific task you want to accomplish and the nature of your data. Here are some of the most common types of models:
- Generative Adversarial Networks (GANs): GANs consist of two neural networks: a generator that creates new data and a discriminator that evaluates the quality of the generated data. They are well-suited for tasks such as image generation and style transfer.
- Variational Autoencoders (VAEs): VAEs are generative models that learn a latent representation of the data. They are often used for tasks like image generation and data imputation.
- Flow-Based Models: Flow-based models are generative models that learn a bijective mapping between the input and output spaces. They are efficient and can be used for various tasks, including image generation and density estimation.
- Autoregressive Models: Autoregressive models generate data sequentially, one element at a time. They are commonly used for tasks like text generation and time series forecasting.
When selecting a model, consider the following factors:
- Task Requirements: What type of output do you want to generate?
- Data Characteristics: What is the nature of your data (e.g., images, text, audio)?
- Computational Resources: How much computational power do you have available?
- Model Complexity: How complex is the model you need?
Training the Model
Training a generative AI model involves feeding it large amounts of data and adjusting its parameters to minimize a loss function. Here are some key steps involved in the training process:
- Data Preprocessing: Ensure that your data is in a suitable format and has been cleaned and preprocessed.
- Model Architecture: Choose a suitable model architecture or customize an existing one to fit your specific needs.
- Hyperparameter Tuning: Experiment with different hyperparameters, such as learning rate, batch size, and number of epochs, to optimize model performance.
- Training: Feed your data into the model and iteratively update its parameters using a gradient descent algorithm.
- Evaluation: Evaluate the model’s performance using appropriate metrics, such as mean squared error (MSE) for image generation or perplexity for text generation.
- Fine-tuning: If necessary, fine-tune the model on a smaller, more specific dataset to improve its performance on a particular task.
How do you deploy Gen AI models?
Once you’ve trained and evaluated your generative AI model, the next step is to deploy it into production and monitor its performance. This involves integrating the model into your existing systems, ensuring its reliability and scalability, and continuously monitoring its performance to identify areas for improvement.

Integration into Existing Systems
- API Integration: If your model is a web-based API, you can integrate it into your existing applications using RESTful APIs or GraphQL.
- Embedded Systems: For embedded applications, you may need to optimize the model for resource-constrained devices and integrate it directly into the software or hardware.
- Cloud Platforms: Consider using cloud-based platforms like AWS, GCP, or Azure to deploy and manage your model. These platforms offer a range of services, including compute resources, storage, and monitoring tools.
Ensuring Reliability and Scalability
- Performance Optimization: Optimize your model for performance, especially if it’s deployed on resource-constrained devices or needs to handle high traffic loads. This may involve techniques like quantization, pruning, or knowledge distillation.
- Fault Tolerance: Implement mechanisms to handle errors and failures gracefully. This might include redundancy, backups, and monitoring systems.
- Scalability: Ensure that your deployment can handle increasing workloads and scale up or down as needed. Consider using cloud-based infrastructure or distributed systems.
Monitoring and Evaluation
- Performance Metrics: Define appropriate metrics to measure the performance of your model. These metrics may vary depending on the specific task, but common examples include accuracy, precision, recall, F1-score, and mean squared error.
- Continuous Monitoring: Implement a system for continuously monitoring the model’s performance in production. This can help identify issues early on and take corrective action.
- A/B Testing: Conduct A/B tests to compare the performance of your model with different versions or alternative approaches. This can help you identify areas for improvement and optimize your model.
- Feedback Loops: Incorporate feedback loops to collect user feedback and improve the model over time. This can be done through surveys, user interviews, or analytics.
Addressing Challenges
- Bias and Fairness: Monitor your model for bias and ensure that it is treating all users fairly.
- Explainability: If necessary, develop techniques to explain the model’s decisions. This can help build trust and transparency.
- Ethical Considerations: Be mindful of ethical implications and ensure that your model is used responsibly.